AMD has published a whitepaper that explains what are the Compute Cores introduced with the recently launched A10-7850K APU.
A Compute Core is any core capable of running at least one process in its own context and virtual memory space, independently from other cores.
A more detailed description of the compute cores can be found in this white paper: Compute Cores.
It other words just empty PR? AMD is pathetic.
What guys from AMD do good – geek presentation slides. NVidia and Intel never have that detalized slides )))
Not PR, not for geeks, for developers, APUs are great – we do some amazing stuff with them (for example use instead of fpu from cpu core) thanks to HSA. I hope that all those APUs will get re-tested after some of our and other 3rd party software hit the market and all those closed minds will open 😉
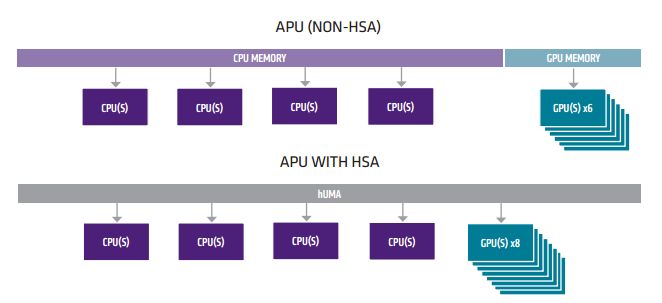
HSA is a major change in computing architecture for many decades. It is finally heterogenous capable when we were promise such capabilities with the limited old architecture. Here are the major changes:
1) Global shared memory managed by hUMA switch not the cpu. Cpu still has its own local L2 private cache but ram is now controlled by hUMA switch. This means cohenency with multiple access such as the VRAM portion reserved for the gpus. ie cpu and gpu has shared access, hence no copy-move operations that were slow in the old architecture. Gpu or any cpu core can have its own privately reserved ram space as well.
2) GPU now has context in the HSA model so they can chew on more than one task. Old model cannot do this!.
3) Heterogenous queuing done by hUMA bus so there is no saturation of RAM access or contention.
What is needed is OS changes in the kernel to improve on memory management taking advantage of hUMA controller and scheduler. OpenCL 2.0 driver support with HSA compliant compiler to manage multiprocessing in an automatic way. Sure manual tuning is possible by code but OpenCL manages most of the complexity, so developers can have as easier time with HSA app development.
It is expected 2X and more performance on average while some apps could get 7X to 10X speed up if their code were parallerized to all cores with little contention for resources.eg heavy vectorized fp can be spread and accumulated with very fast completion times.