
OpenCL Surface Deformer demo with a mesh of 512×512 vertices
Related articles:
- GPU Computing: GeForce and Radeon OpenCL Test (Part 1)
- GPU Computing: GeForce and Radeon OpenCL Test (Part 3)
- GPU Computing: GeForce and Radeon OpenCL Test (Part 4 and conclusion)
First OpenCL Test: Surface Deformer
The surface deformer is the first demo I coded in OpenCL. When I saw the simpleGL sample in NVIDIA OpenCL SDK, I decided to improve it by rendering a real mesh with lighting instead of a grid of flat colored vertices.
I started the development of the demo on a GeForce GTS 250 and in the first versions I used a mesh plane of 800×800 vertices (around 1.2 millions triangles). The mesh deformation ran at about 6 FPS… ouch, OpenCL is not really efficient! On a GTX 295, the demo ran at 14 FPS. Then I tested the demo on a Radeon HD 5770. The difference was just not possible: 51 FPS for the HD 5770!!!
Two explanations: either Radeons are very very powerful or there is a problem somewhere. Actually both explanations are true: Radeon HD 5000 is a fast card and there are problems with NVIDIA OpenCL driver.
The first problem of GeForce was the ForceWare 190.89. A simple update to ForceWare 195.39 was enough to improve a bit the FPS: 12 FPS on the GTS 250 and 21 FPS on the GTX 295. And with the latest WHQL R195.62, NVIDIA’s performance finally reached AMD one. So all GeForce tests, in this article and in the following ones, have been done with R195.62.
But it’s still interesting to look at the reasons of poor performance of NVIDIA’s first OpenCL drivers.
After some tests, reading and discussions, I found two things to optimize: transcendental functions and OpenCL work group size.
Transcendental functions (sine, cosine, …) are functions processed by SFU or Special Functions Unit on a GeForce. In the mesh deformer kernel, the sine function is called twice (once for the position and once for the normal). OpenCL defines three kind of functions for math functions like sine or sqrt: native, half and regular functions.
An exemple of a regular function call is:
y = sin(x);
An exemple of a native function call is:
y = native_sin(x);
And an exemple of a half function call is:
y = half_sin(x);
From the OpenCl specification:
A subset of functions from table 6.7 that are defined with the native_ prefix. These functions may map to one or more native device instructions and will typically have better performance compared to the corresponding functions (without the native__ prefix) described in table 6.7. The accuracy (and in some cases the input range(s)) of these functions is implementation-defined.
On GeForce GPU, transcendental functions functions are processed by two separate SFUs in each streaming multiprocessor (or OpenCL compute unit) and on a Radeon GPU transcendental functions are processed by a special unit in each vec5 processor.
On the GTS 250, the use of native functions made the FPS went up from 12 FPS to 19 FPS. It’s cool but we can do better with explicit work group size.
There are two way to run an OpenCL kernel: by explicitly specifying the work group size (global and local) or by letting the OpenCL driver doing the job (implicit work group size – global only). A work group size is equivalent to a CUDA block thread size. Work group size specification is also called NDRange configuration:
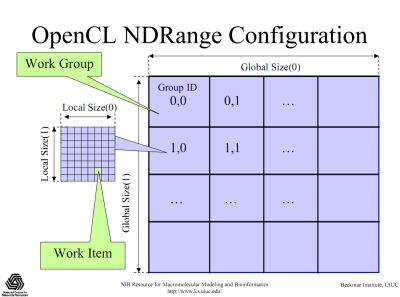
In the first version of the surface deformer demo, I didn’t specify the work group size. For the GeForce GTS 250, the explicit specification of work group size has had a very important impact on the FPS.
GeForce GTS 250 + R195.39:
- 800×800 implicit work group size: 12 FPS
- 800×800 implicit work group size + native_ func = 19 FPS
- 800×800 explicit work group size: 31 FPS
- 800×800 explicit work group size + native_ func = 32 FPS
On a Radeon HD 5000, an explicit work group size has no perceptible impact. Same thing for native_ functions.
Now with R195.62, there is no longer difference between explicit and implicit workgroup size like for AMD OpenCL driver. NVIDIA has improved work group size management and performance as well.
Same thing for native functions.
On the GeForce with first OpenCL drivers, native_sin() function is processed by the SFUs and is faster than sin() which seems to be processed by regular ALUs. On a Radeon, seems that native_sin() and sin() functions are both processed by the special unit of a vec5 processor because native_sin and sin are both fast.
Now it’s time to see some performance graphs. All tests have been done with GPU Caps 1.8.2 PRO (GPU Caps Viewer 1.8.2 is also fine but there is no benchmarking support) with the following system:
– Windows Vista SP2 32-bit
– system memory: 2GB 1333 DDR3
– CPU: Intel Core 2 Extreme CPU X9650 @ 3.00GHz
– NVIDIA driver: R195.62
– AMD driver: Catalyst 9.12 hotfix
The mesh plane is initialized with 511×511 segments which is equivalent to 512×512 vertices. This mesh has 522,242 faces and 262,144 vertices. The demo shows a surface deformed by a kind of sine wave. An OpenCL kernel performs all the hard work. It computes the vertices position (surface deformation), and computes vertices normal for nice lighting. Once all calculations are finished, all data is sent to OpenGL VBOs (vertex buffer object). The rendering is done with an OpenGL 3 context.
The X axis represents the average FPS.

Radeons lead the test. But there is a weird result: a GeForce GTS 250 is faster than a GTX 280!!! Since the GPU architecture of both cards is different, I think the GT200 architecture is currently not properly exploited by NVIDIA OpenCL driver. Or maybe there is a problem in my OpenCL code and an optimization must be done for GT200 GPU (hurrah for different code paths!!).
Other result: the HD 5870 is not twice faster than Radeon HD 5770. At the hardware level, the HD 5870 is twice the performance of HD 5770. But in this particular test, this small difference is explained by the OpenCL driver intrusion or overhead. The GPU Cypress is really fast and the current OpenCL kernel is not enough complex to keep it busy during many GPU cycles. In short, the OpenCL calls are costly and then minimize the performance difference between both GPUs. To see an important difference, you have to increase the kernel workload with the following parameter:
GpuCapsViewer.exe /cl_kernel_workload_sin=10000
This parameter allows to increase the workload of the OpenCL kernel by adding a loop made of some sin / cos / sqrt calculations. cl_kernel_workload_sin specifies the number of loops. By default cl_kernel_workload_sin = 0. This transcendental loop does not affect the surface deformation. It’s just a compute unit processing power eater. 10000 loops is most representative of Radeon GFlops power: in this case, the OpenCL driver intrusion is minimal and we see the Radeon HD 5870 is around twice faster than the HD 5770. Warning: 10000 is a very high value for GeForce…
PC Inpact has more results on the surface deformer demo with Windows 7. For french readers, jump HERE and HERE.
hmm,
we already knew that ATi’s GPUs are fast(er) at running small kernels/shaders, but how do they perform at very complex ones (e.g. FFT water computation)?
In theory NVIDIA should have less but more powerful compute units, so does it really performs better at such tasks?
The main problem you’re having is that the GF need to manage with caution the local memory.
See the CUDA’s shared memory bank conflicts for more info.
Also, caution with the uint locals.
Pingback: [TEST] GPU Computing – GeForce and Radeon OpenCL Test (Part 1) - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com